
01
Zero-Friction Intent Interfaces
The interface disappears. Users state goals; AI executes the backend action.

Most organisations' Generative AI experience stops at conversational interfaces. The technology's actual surface area — reasoning over proprietary data, orchestrating multi-step workflows, generating structured outputs from unstructured inputs — is where enterprise value concentrates. The gap between what people think GenAI does and what it actually delivers in production is where strategic advantage lives.
Gain inspiration from GenAI archetypes enterprises have built, each grounded in the capability stack and governance disciplines that make them durable.
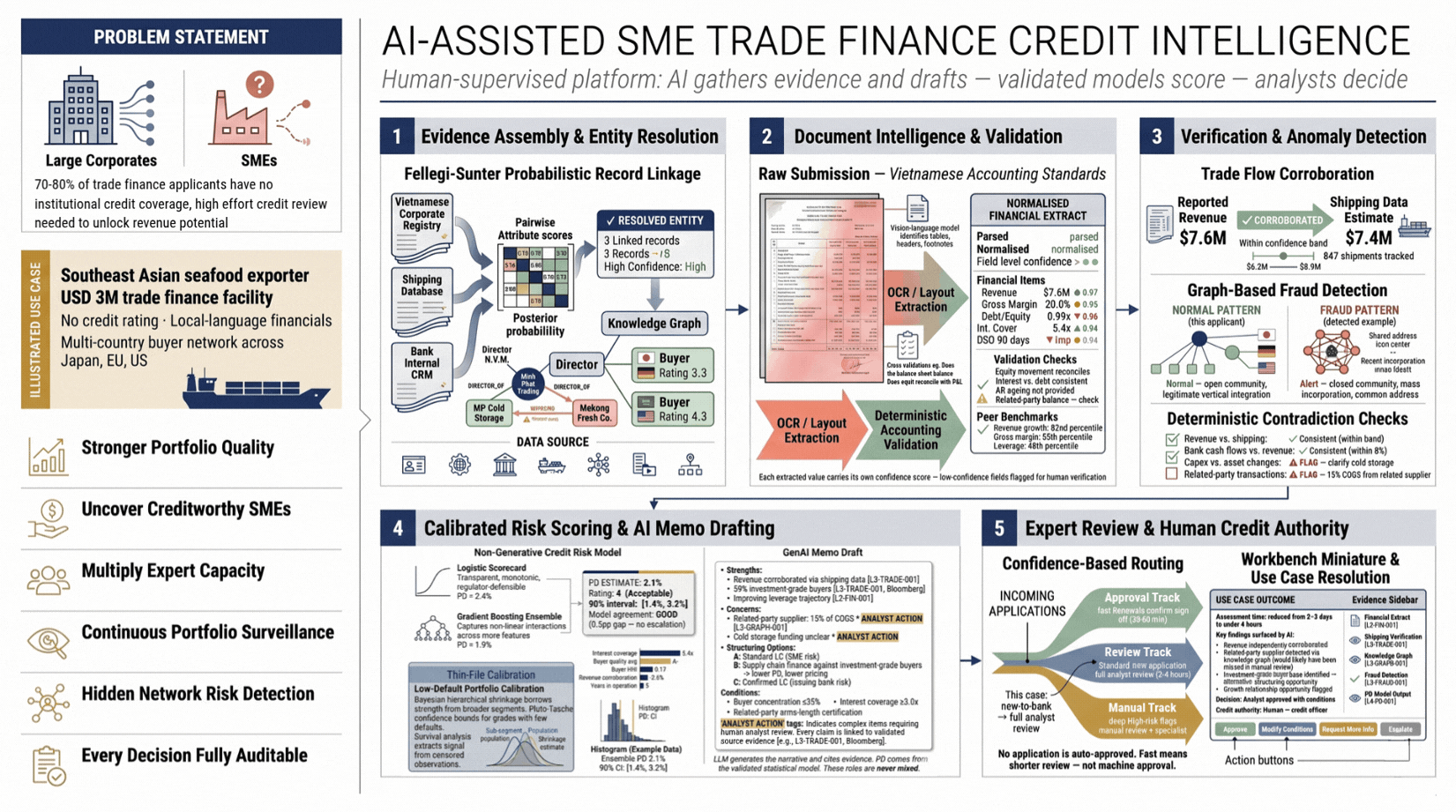
Traditional credit scoring misses creditworthy SMEs with thin banking records. This system assembles evidence from shipping records, corporate registries, and trade flow data. Assessments complete in minutes, the portfolio expands without adding analysts, and hidden network risks surface.
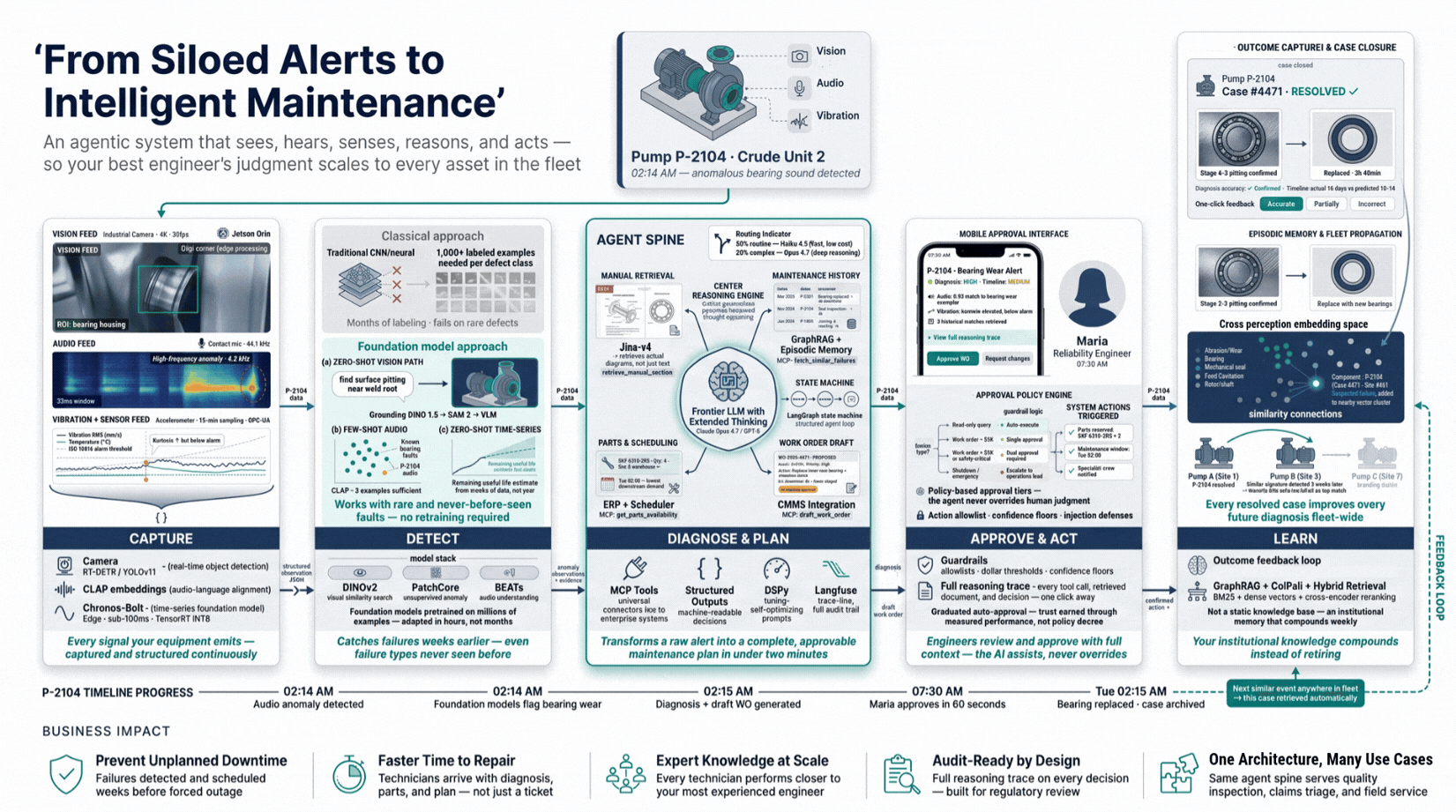
Unplanned downtime costs more than scheduled maintenance. Fusing camera feeds, vibration sensors, and audio analysis, this system detects failure signatures before breakdown, automatically scheduling repair and logging the decision. One architecture covers inspection, claims triage, and field service.
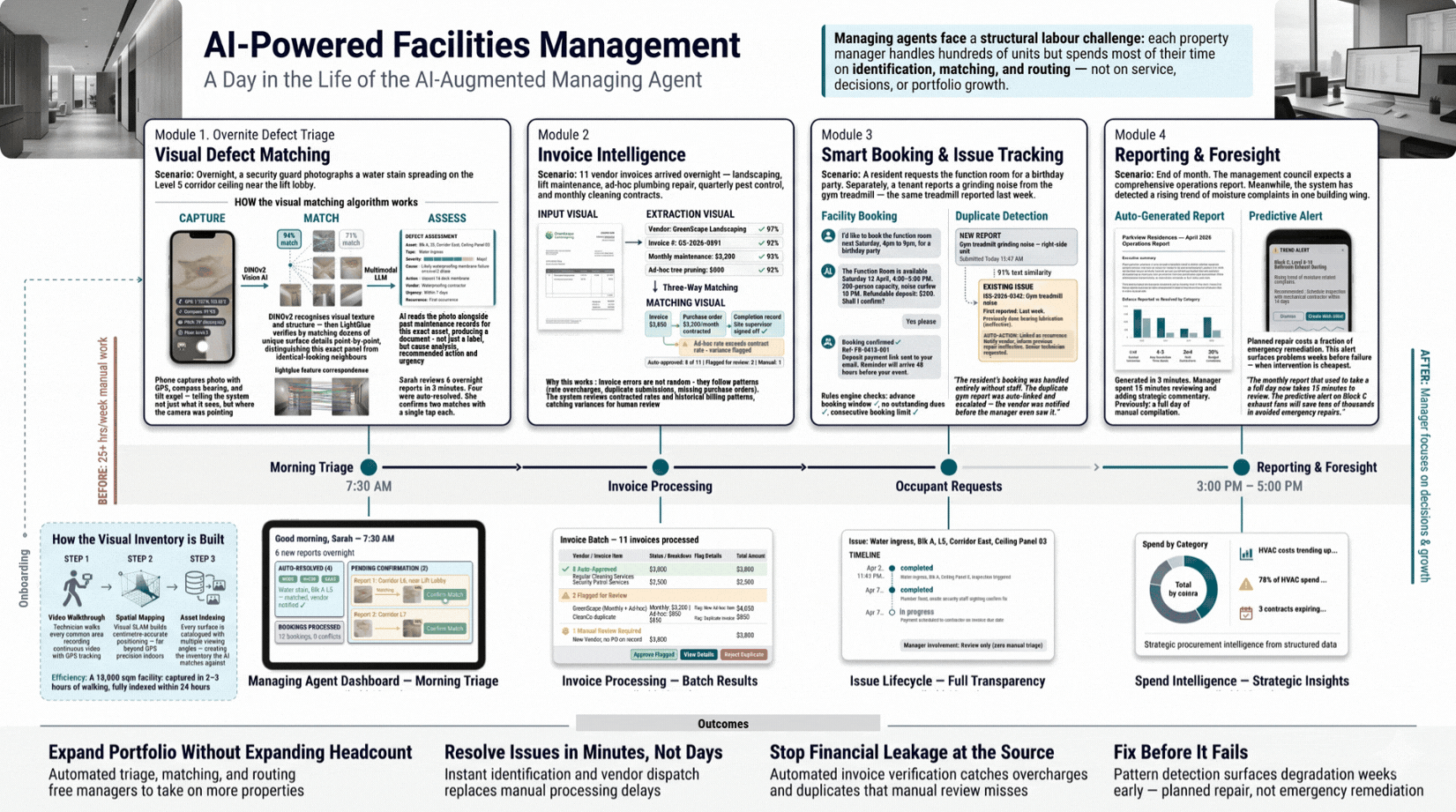
Portfolio growth is constrained by how many units a manager can handle. Visual defect matching, invoice fraud detection, and predictive maintenance run in parallel, compressing issue resolution from days to minutes and enabling one manager to cover what previously required a full team.
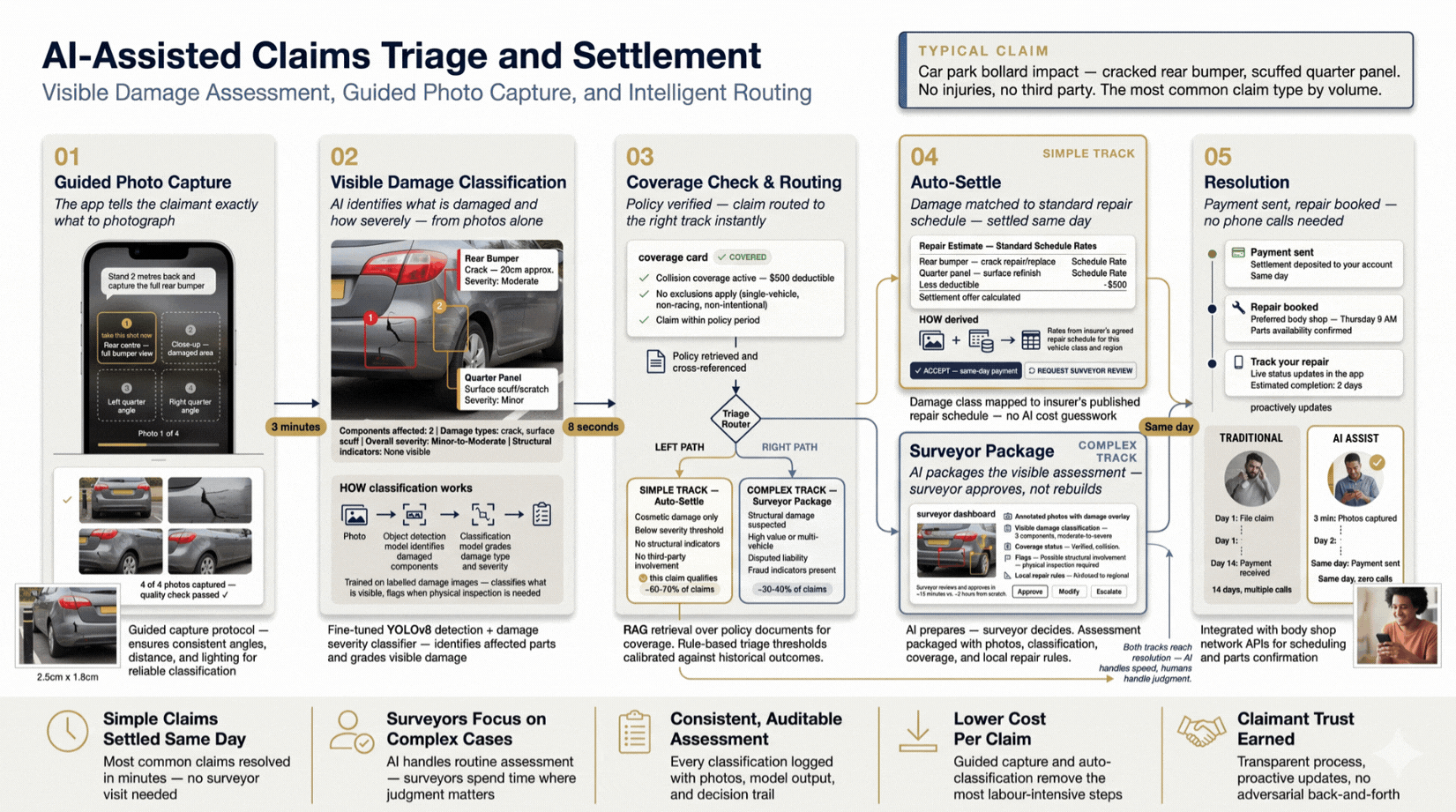
Simple claims that took 14 days now settle the same day. AI classifies damage from guided photos, verifies coverage, and releases payment, all without a phone call. Surveyors redirect to complex cases requiring judgement. Cost per claim drops; consistent, auditable assessment improves defensibility.
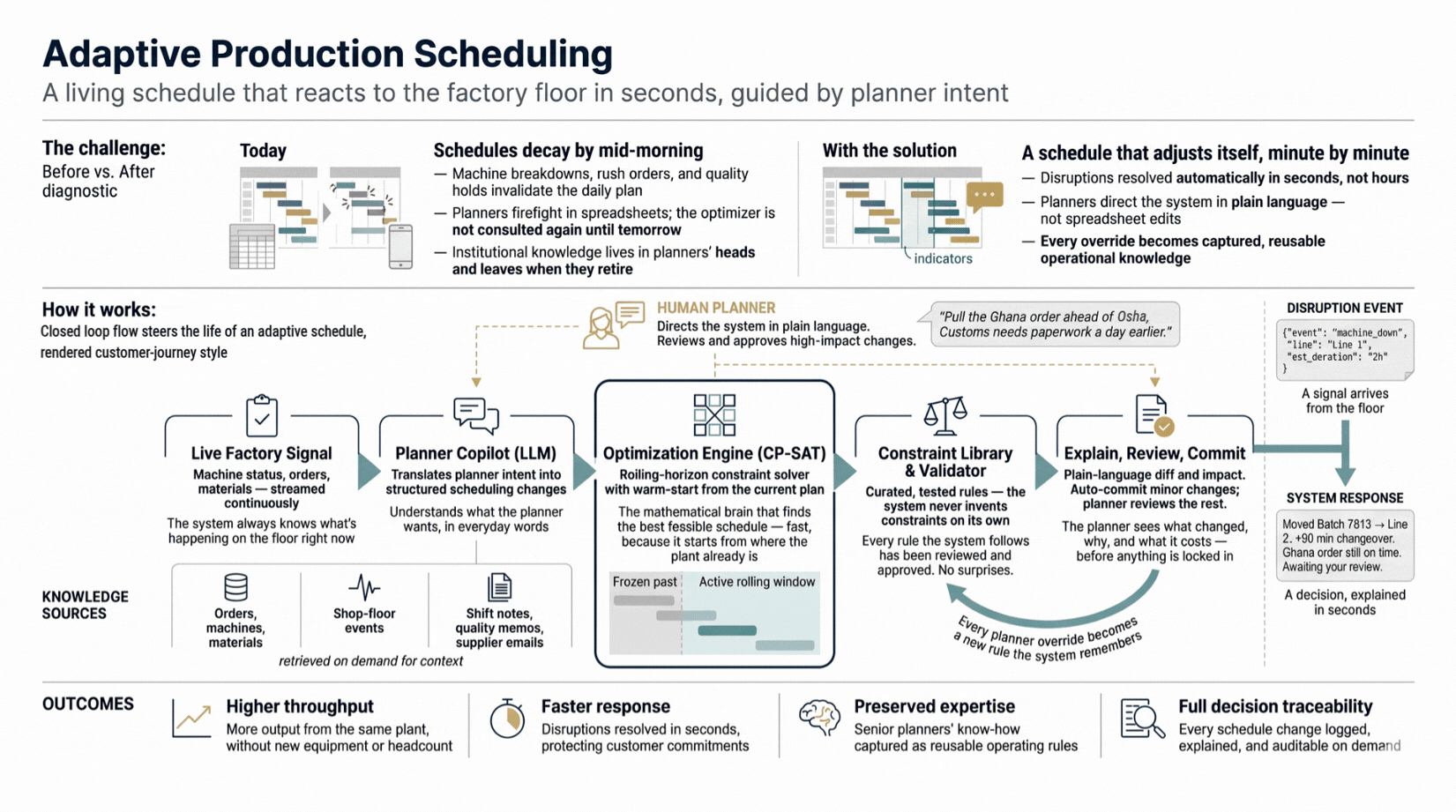
Manually rescheduling around machine breakdowns, material shortages, and rush orders takes hours. This system absorbs disruptions in seconds. A constraint-satisfaction optimiser driven by plain-language planner input, with full decision traceability and captured expert rules that outlast individual planners.
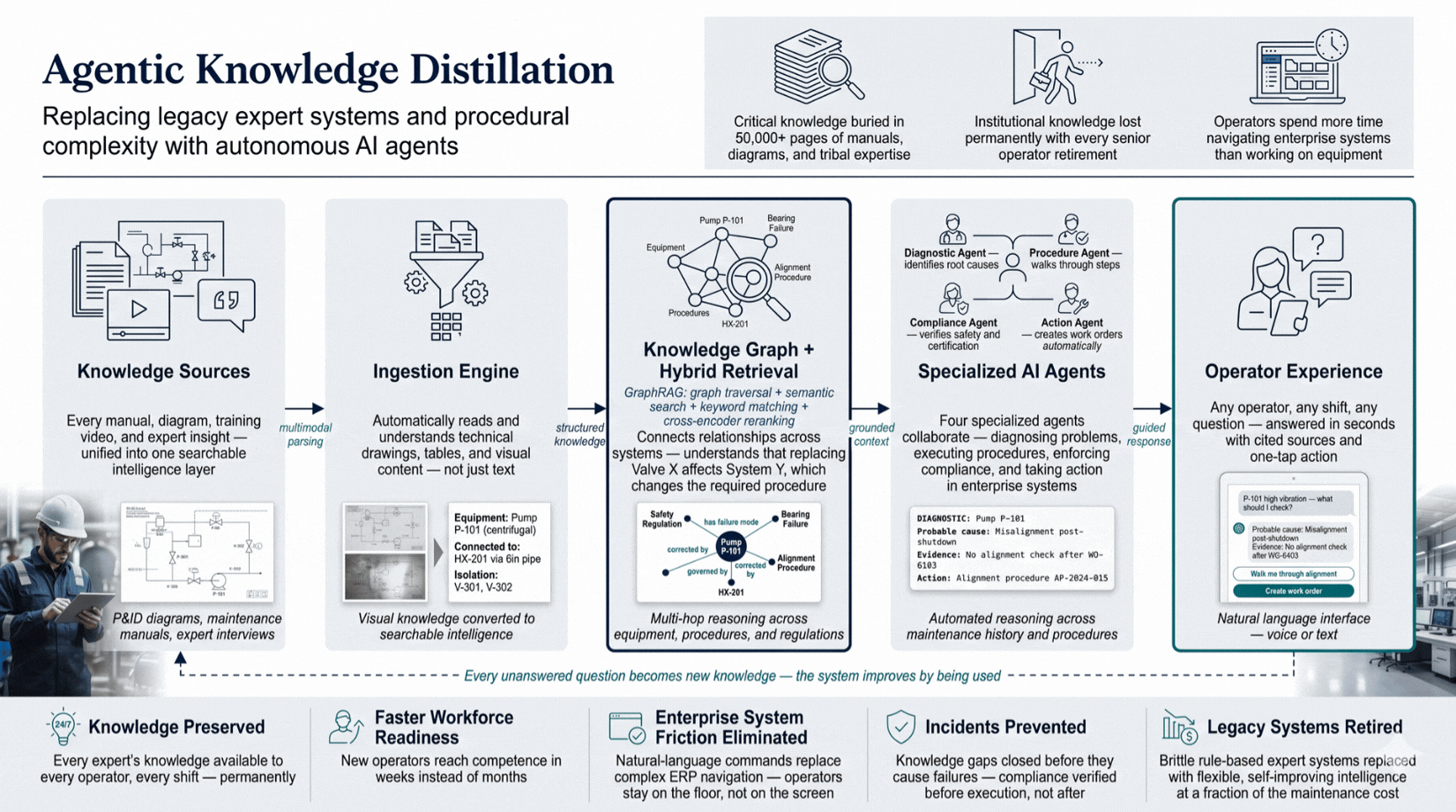
Institutional expertise is locked in manuals, diagrams, and the heads of long-tenured employees. This system ingests all of it into a queryable knowledge graph, giving any operator cited answers in seconds. Knowledge stops leaving with retirements. The system improves every time it's used.
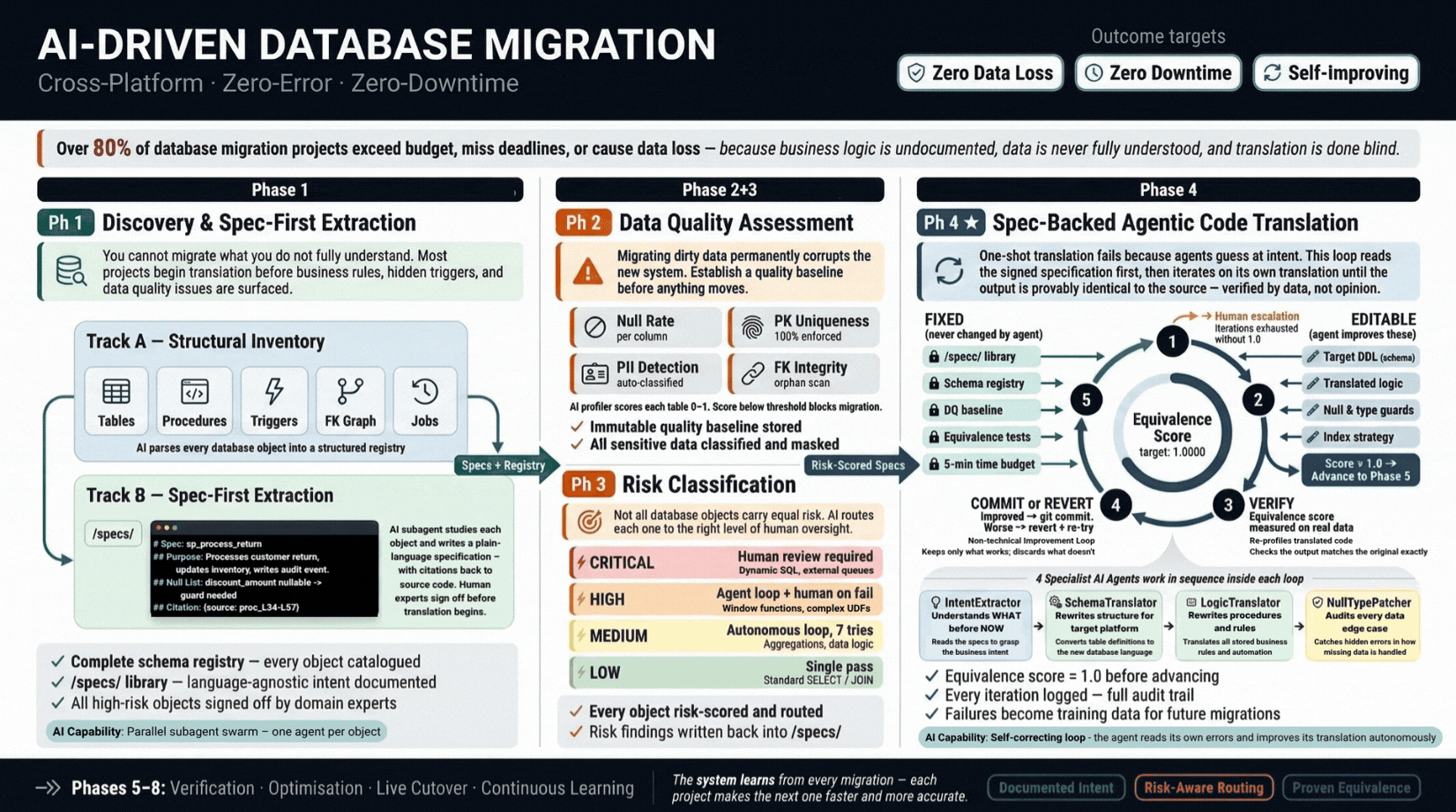
Over 80% of database migrations exceed budget or miss deadlines. A spec-first agentic pipeline inventories schemas, assesses data quality, detects PII, and verifies functional equivalence at each stage, eliminating the risk accumulation that causes traditional migrations to fail at the finish line.
Complex freight proposals require 12 people and 5 weeks of analysis. This workbench ingests RFQs, generates feasible itineraries, runs pricing Monte Carlo simulations, and produces AI-drafted proposals, compressing the cycle to 3 days with a pricing manager and network planner. More bids, better win rates.
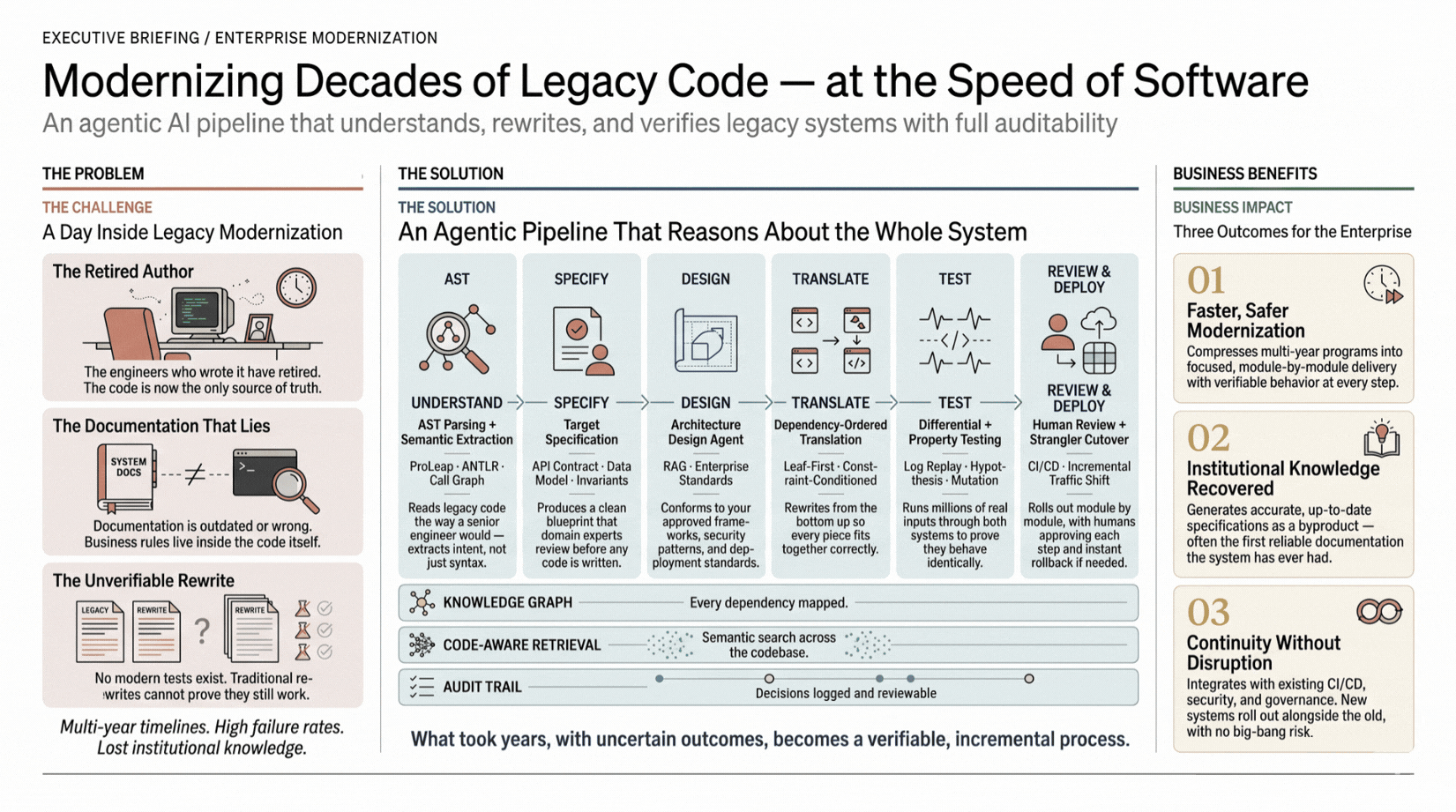
Legacy code carries institutional business logic that no one has fully documented. AST parsing extracts that logic into specs; agentic translation rebuilds it in modern architecture; differential testing verifies equivalence. Accurate specs are a byproduct. Risk is incremental and verifiable, not deferred to a big-bang cutover.
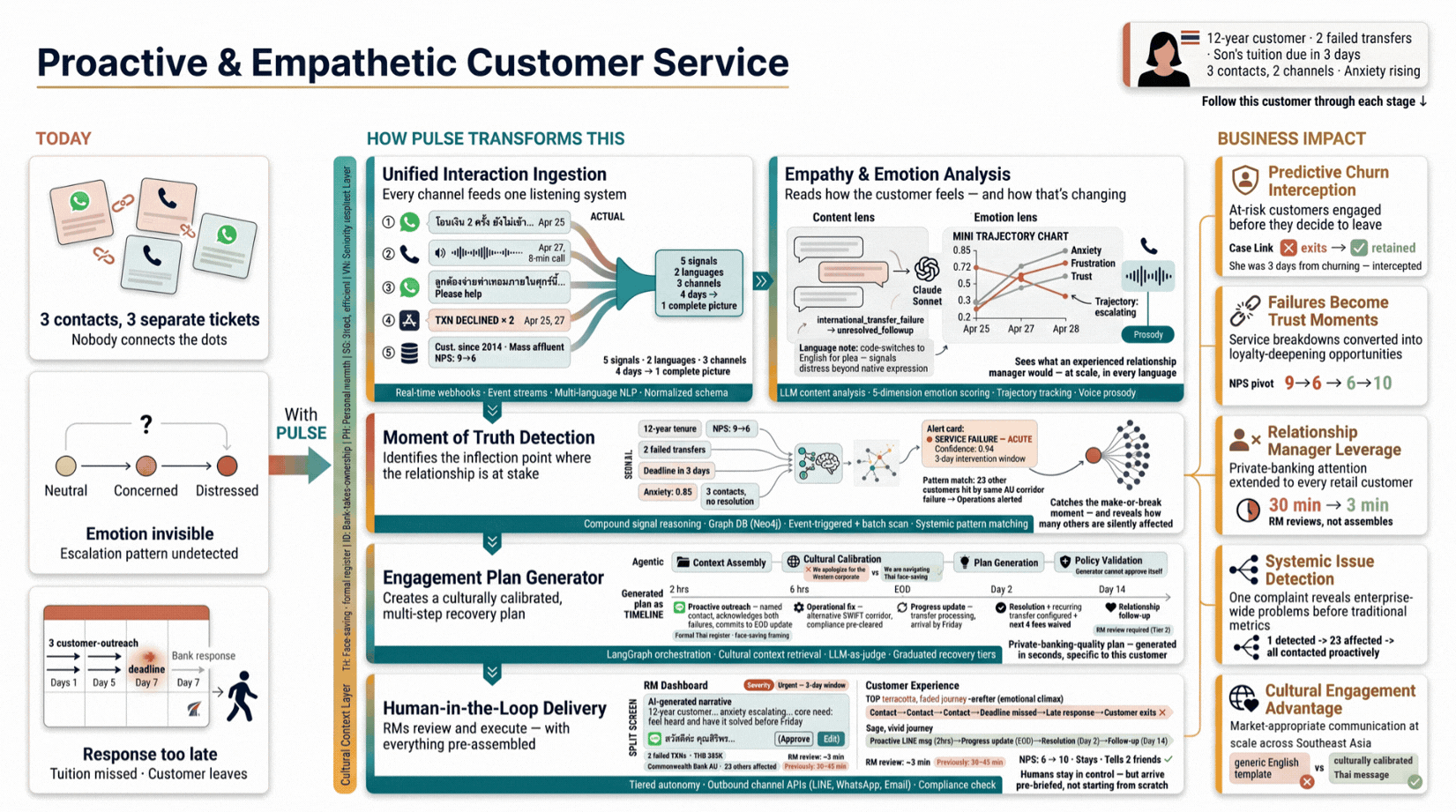
Most churn is detectable before the customer decides to leave. This system reads emotion trajectories across every channel, identifies the moment a relationship is at stake, and generates a recovery plan calibrated to the customer's full history, giving relationship managers the signal and context to intervene in time.
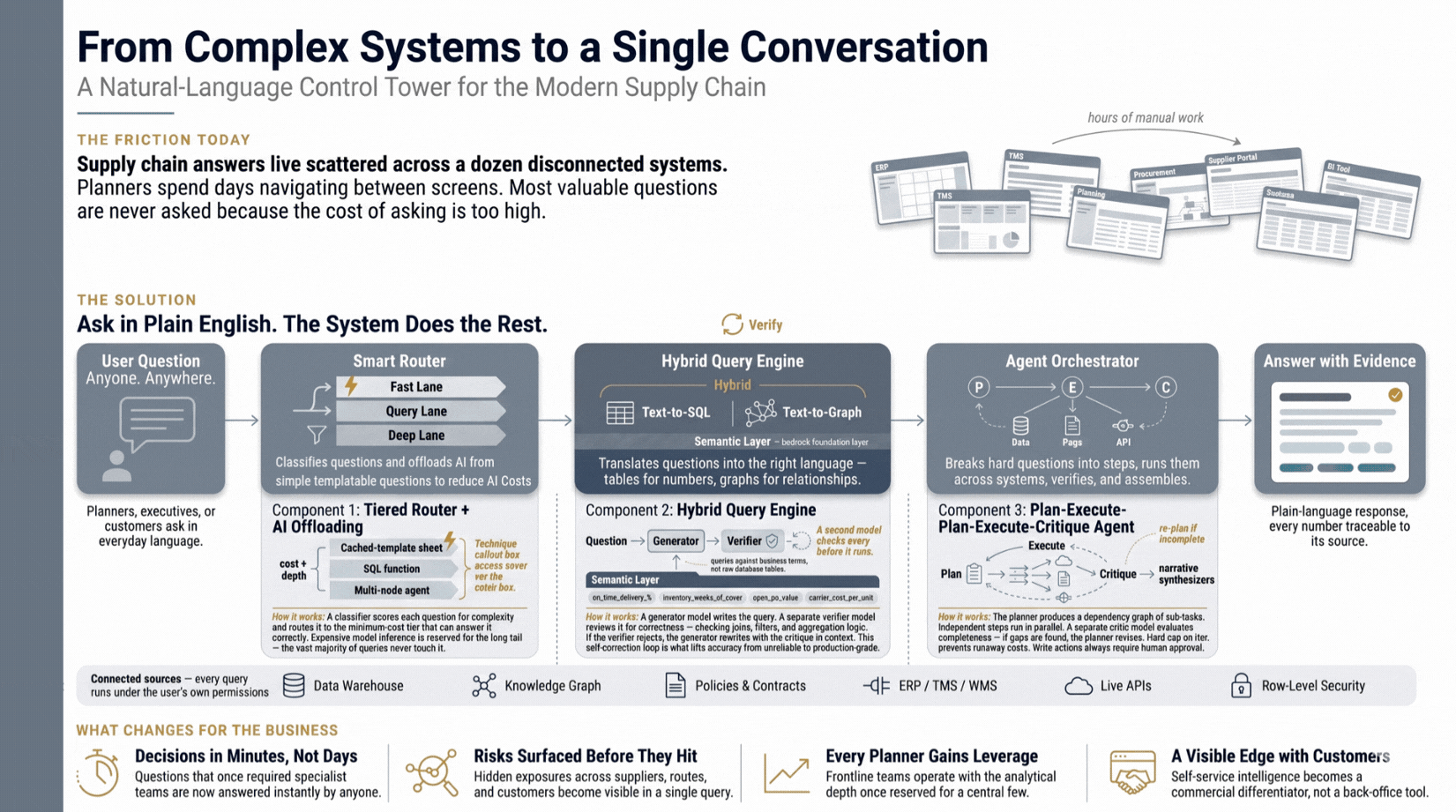
Supply chain visibility is gated by data analysts and SQL. This control tower routes plain-language questions through a hybrid query engine across ERP, TMS, and WMS, surfacing risks before they reach structured data and giving frontline planners the analytical depth previously reserved for central teams.
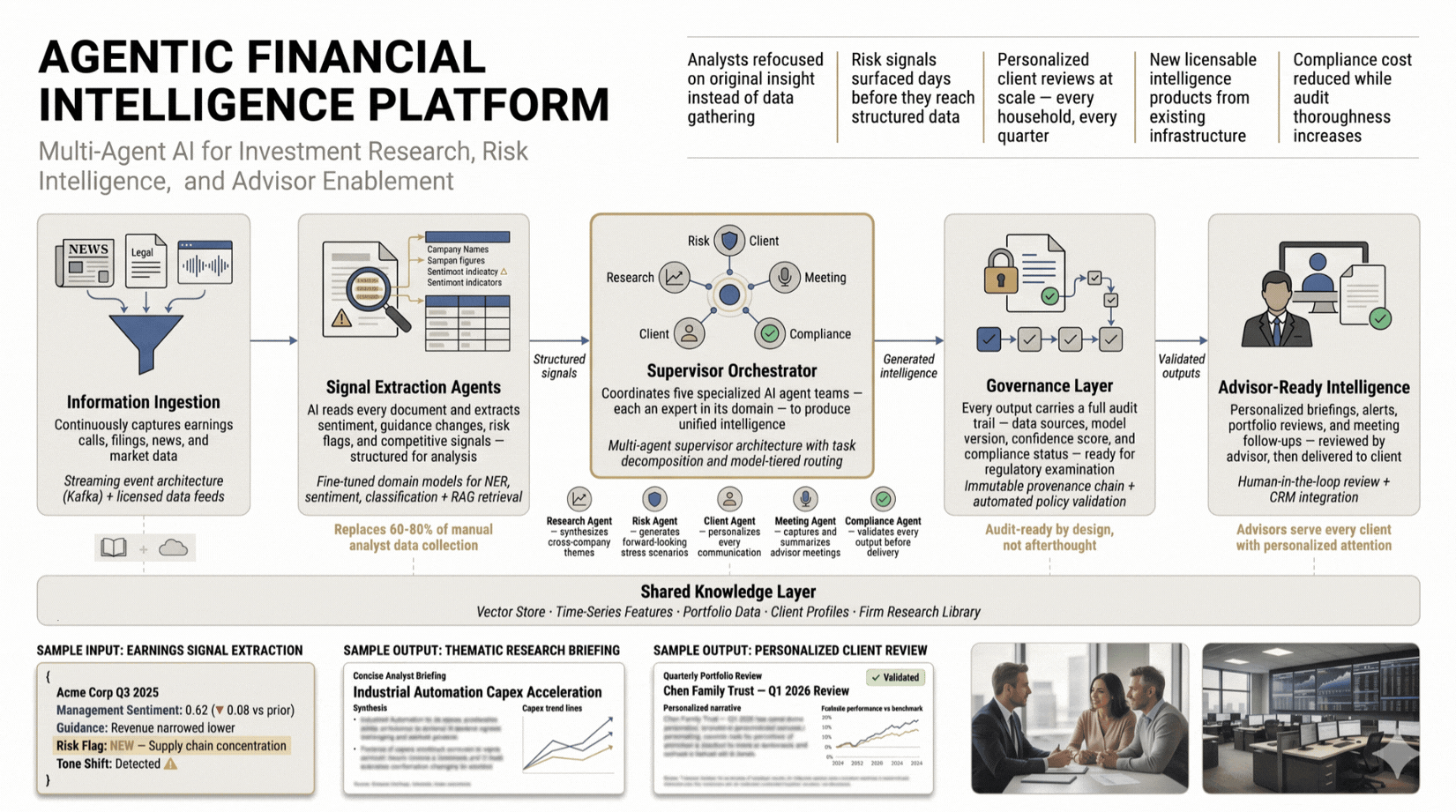
Analysts spend 60–80% of their time gathering data, not generating insight. Five specialised agent teams process earnings calls, legal filings, and market signals continuously, surfacing risk signals days before structured data reflects them, scaling personalised client reviews, and reducing compliance cost while improving audit depth.
The immediate applications (chatbots, content generation, code assistance) are the visible surface. Beneath them, generative AI is restructuring assumptions that have governed enterprise operations for decades. These are the shifts that separate organisations positioning for the next era from those optimising the current one.
The interface disappears. Users state goals; AI executes the backend action.
AI reads tone and cultural context in real time, adapting language, pace, and register seamlessly.
One persistent concierge. Infinite memory. Every channel, unified.
The ultimate skill-leveller: average employees perform at expert levels. The organisational pyramid flattens.
Expertise trapped in documents and long-tenured heads — queryable by anyone, on day one.
By 2030, machine customers could influence $18T in purchases. B2B becomes machine-to-machine.
AI agents analyse terms, propose counteroffers, and close deals simultaneously, across thousands of suppliers.
Build for the moment. Discard when done. The backlog dissolves.
Every analog process, paper form, and unstructured source becomes structured and actionable.
The 20% of edge cases consuming 80% of operational time. Automatable with GenAI reasoning.
The public narrative centres on chat interfaces and content generation. The enterprise reality is broader, and the limitations are more specific than most organisations realise.
A foundation model generates text. An enterprise system requires retrieval, adaptation, multi-modal understanding, tool access, autonomous orchestration, and systematic evaluation. Each layer addresses a specific limitation, and each introduces architecture decisions that determine production outcomes.
Production GenAI systems operate across every dimension of enterprise performance. Each archetype below is built on the capability stack above, and each demands the governance and production engineering that follows.
Every GenAI deployment operates in a risk landscape. The consultancies that name risks explicitly and engineer against them systematically deliver systems that survive production. The ones that minimise them deliver pilots that never scale.
Frameworks describe the territory. These are lessons from navigating it, patterns from enterprise GenAI deployments, each learned the hard way so the next engagement starts further ahead.
GenAI: zero-shot reasoning, language interpretation, novel-task generalization. Cannot guarantee deterministic outputs or predictable accuracy on structured decisions.
ML: consistent scores with quantified error bounds, sub-10ms inference, reproducible outputs. Cannot generalize beyond its training distribution or interpret unstructured inputs without feature engineering.
Combined: GenAI's flexibility produces the features ML needs. ML's precision produces the context GenAI reasons over. Each makes the other more effective.
In practice: customer revenue protection. GenAI reads support transcripts and contract correspondence zero-shot, extracting intent signals no structured field captures. An ML survival model scores 90-day churn probability from those signals plus usage and billing data. A GenAI agent drafts retention outreach tailored to the specific concerns identified. Better signals → better scores → better timing → better conversations.

The question is not whether GenAI can create value, but which opportunities are highest-leverage, what architecture they require, whether your data and infrastructure support them, and what the realistic path from pilot to production looks like. A diagnostic conversation applies this framework to your specific situation.
