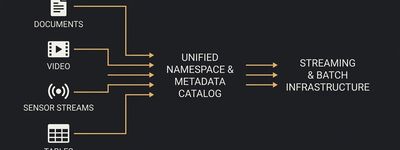
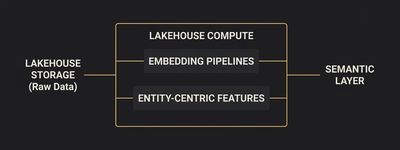
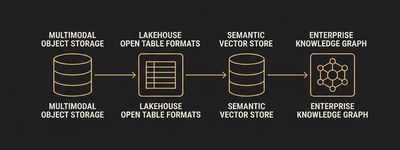
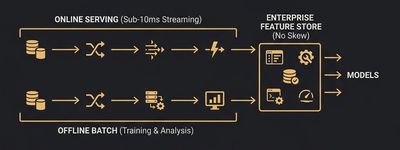
Cloud-Native: Databricks, Snowflake, BigQuery, Synapse, Vertex AI, SageMaker. Hyperscaler-managed services deliver the fastest time-to-value where data residency and sovereignty constraints do not bind. The vast majority of greenfield AI workloads start here, and should, unless there is a specific reason not to.
On-Premise: Cloudera Data Platform, Red Hat OpenShift AI, NVIDIA AI Enterprise, Kubernetes-native data platforms. Required when sensitive intellectual property, regulated data, or latency-bound workloads cannot reasonably go to public cloud. Every layer is the team's to operate, and the engineering payoff is full control of the stack.
Air-Gapped & Sovereign: Defence, classified government, sensitive financial workloads. The full AI stack (model serving, vector stores, feature stores, lineage tooling) operating without internet egress, often without inbound updates for extended windows. Open-weight models, locally-hosted embedding generation, and air-gap-friendly observability are the building blocks. We have built in this context; the constraint set is uncompromising.
Hybrid and Edge: Edge inference brings low latency intelligence to the manufacturing floor, retail store, telecom base station, autonomous vehicle, point-of-sale. Leveraging features computed centrally and shipped to the edge, retraining triggered when edge drift is detected. The architecture is harder than either pure-cloud or pure-on-prem; the deployment surface area is the reason it is increasingly common.